
Cloud Operations & Security as a Managed Service
Overview
As a Managed Services Provider (MSP), we do not operate as a reactive “ticket-resolution” team. We function as an embedded Cloud Reliability & Security partner, delivering structured, measurable, and governance-driven operations across multi-cloud environments.
Our operating model integrates:
- SRE-led reliability engineering
- GitOps-driven change governance
- Structured Runbooks & Playbooks
- Embedded DevSecOps controls
- Continuous observability & FinOps discipline
This framework ensures that customer environments remain stable, secure, compliant, and cost-efficient while enabling controlled innovation.
Our Managed Services Operating Philosophy
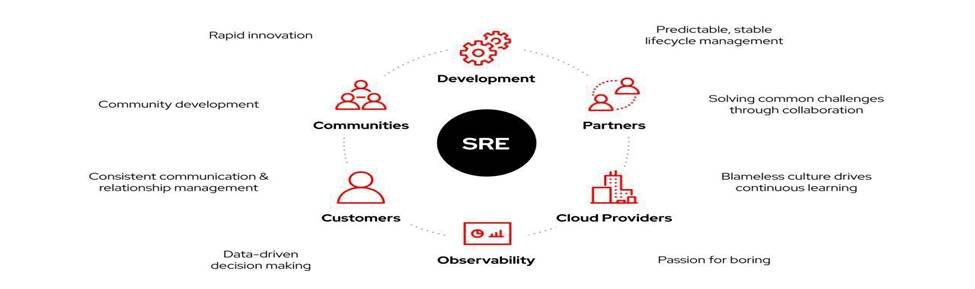
We operate on a simple but powerful principle:
Reliability, Security, and Governance must be engineered and not improvised.
Every client engagement is structured under a standardized operational framework that scales across AWS, Azure, GCP, Kubernetes, containerized workloads, and AI-driven platforms.
1. Governance-First Operations
Cloud operations without governance create drift, risk, and audit gaps.
Our framework begins with a structured control model.
Structured Change Management
All infrastructure, configuration, and policy changes must:
- Be declared as code
- Pass peer review
- Include rollback plans
- Be traceable to business justification
- Follow defined production change windows
We enforce a no-unmanaged production-change policy.
This ensures:
- Audit traceability
- Reduced human error
- Controlled release velocity
- Predictable production stability
Clear Accountability (RACI)
We define roles between:
- Customer engineering teams
- Our Cloud Operations team
- SRE specialists
- Security operations
Accountability is never ambiguous which significantly reduces incident friction and escalation ambiguity.
2. SRE-Led Reliability Engineering
Our operating model is heavily influenced by Site Reliability Engineering principles.
We treat reliability as a measurable engineering discipline.
Service Level Engineering
For every managed workload, we define:
- Service Level Indicators (SLIs)
- Service Level Objectives (SLOs)
- Error Budgets
- SLA reporting cadence
Rather than simply “keeping systems up,” we:
- Quantify acceptable risk
- Control release velocity using error budgets
- Prioritize stability work when reliability degrades
This creates a healthy balance between innovation and operational discipline.
3. GitOps as the Operational Backbone
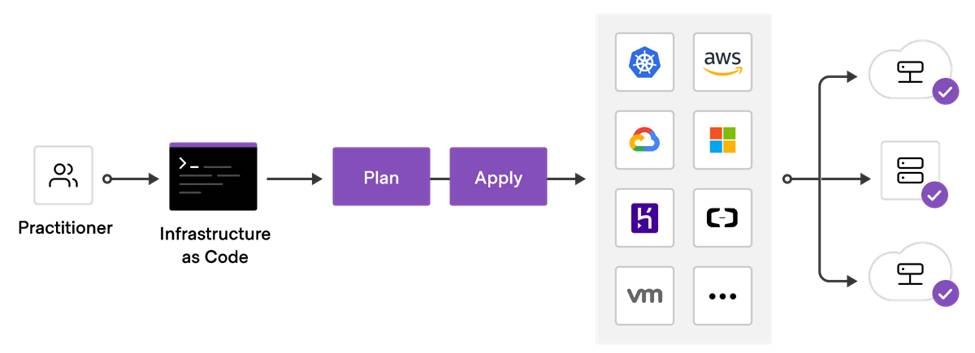
Git is our single source of truth.
All infrastructure and application configurations are maintained declaratively using tools such as:
- Terraform
- Argo CD
- Flux
- GitHub
What This Means for Clients
- No undocumented production changes
- Drift detection across environments
- Version-controlled rollback capability
- Peer-reviewed deployments
- Automated validation gates
Production is never altered manually. It is reconciled automatically to match the declared state.
This dramatically reduces configuration drift and operational surprises.
4. Runbooks: Institutionalized Operational Knowledge
Most organizations rely on tribal knowledge. We eliminate that risk.
For every managed platform, we create structured technical runbooks covering:
- Infrastructure failures
- Kubernetes and container recovery
- Load balancer degradation
- Certificate expiry
- Database failover
- IAM permission issues
- GPU resource saturation (AI workloads)
Each runbook includes:
- Trigger conditions
- Impact analysis
- Step-by-step remediation
- Validation checklist
- Escalation matrix
- Automation opportunity tracking
This ensures consistent recovery execution regardless of which engineer responds.
5. Playbooks: Process Discipline During Critical Events
Beyond technical recovery, enterprise operations require structured response processes.
Our playbooks govern:
- P1 outages
- Security incidents
- Data exposure risks
- Cloud cost spikes
- Regulatory audit scenarios
- Zero-day vulnerability response
Each playbook clearly defines:
- Incident commander role
- Communication cadence
- Stakeholder updates
- Containment strategy
- Root cause analysis template
- Preventive control integration
We conduct blameless postmortems and feed learnings directly into automation.
6. Embedded Security Operations
Security is not a separate department, it is part of the operational fabric.
Our managed framework includes:
- Least privilege IAM enforcement
- Network segmentation & zero-trust design
- Encryption at rest and in transit
- Container and dependency scanning
- Policy-as-code guardrails
- Continuous vulnerability monitoring
- Runtime anomaly detection
Security scanning is integrated into CI/CD pipelines using tools such as:
- Checkov
- Dependabot
This ensures that vulnerabilities are caught before reaching production.
7. Observability & Transparency
We implement full-stack observability aligned to the Four Golden Signals:
- Latency
- Traffic
- Errors
- Saturation
Our monitoring model includes:
- Centralized logging
- Metrics dashboards
- Distributed tracing
- Severity-based alerting (P1–P4)
Clients receive structured operational reporting that includes:
- SLA compliance
- Incident metrics
- Change success rates
- Cost optimization insights
8. FinOps Operating Model (Cost as an Engineering Discipline)
Cloud spend is variable and dynamic.
Without active governance, costs drift silently.
We integrate FinOps directly into Cloud Operations.
8.1 Cost Visibility & Allocation
We enforce:
- Tag-based cost allocation
- Environment-based cost segmentation
- Application-level cost mapping
- Team-level accountability
This ensures transparency across:
- Dev / Stage / Prod
- Business units
- AI workloads
- GPU usage clusters
8.2 Continuous Cost Optimization
Our FinOps cycle includes:
Threat Detection & Security Operations
- Idle resource identification
- Orphaned storage cleanup
- Rightsizing recommendations
- Spot usage analysis
- Savings plan / reservation evaluation
Quarterly Optimization
- Architecture efficiency review
- Storage tiering strategy
- Data lifecycle policy refinement
- GPU cost-performance benchmarking
8.3 Cost Guardrails
We implement:
- Budget thresholds
- Alerting for cost anomalies
- Automated shutdown for non-production idle resources
- Resource quota enforcement
- Cost spike investigation playbooks
FinOps is integrated into the same incident lifecycle as reliability.
8.4 AI / GPU Cost Governance
For AI workloads:
- GPU utilization tracking
- Inference cost-per-request monitoring
- Model performance vs cost evaluation
- Idle GPU detection
- Concurrency efficiency analysis
- Cost-per-inference becomes a measurable KPI.
9. Continuous Improvement & Resilience Testing
Operational maturity requires constant validation.
Quarterly practices include:
- Disaster Recovery drills
- Game Days
- Security posture reviews
- FinOps optimization cycles
- Capacity forecasting
- Architecture review boards
We don’t wait for failure to test resilience.
10. Measurable Outcomes for Clients
Our structured operating model consistently delivers:
Dimension | Impact |
Reliability | Reduced MTTR and incident recurrence |
Security | Lower vulnerability exposure window |
Governance | 100% change traceability |
Stability | Reduced deployment failure rate |
Cost | Structured cloud cost control |
Audit Readiness | Continuous compliance posture |
Clients gain operational predictability and not just monitoring coverage.
What Differentiates Our Managed Services?
We do not:
- Operate via ad-hoc console changes
- Rely on undocumented troubleshooting
- Separate security from operations
- Measure success only by ticket volume
We do:
- Engineer reliability through SRE discipline
- Use GitOps as operational control
- Institutionalize knowledge via runbooks
- Govern change velocity using error budgets
- Embed security and compliance by design
- Provide measurable operational KPIs
Conclusion
Cloud environments are complex, distributed, and constantly evolving. Managing them effectively requires more than tools, and it requires a disciplined operational framework.
Our Managed Services model provides:
- Engineering rigor
- Governance structure
- Security integration
- Operational transparency
- Scalable reliability
- Cost-efficient
Our Managed Services framework ensures all five dimensions operate cohesively not independently.
We do not simply “manage infrastructure.”
We operate and secure mission-critical cloud platforms with engineering precision.
Search
Get in Touch
We’re trusted by over 5000+ clients. Connect with us to explore how our Cloud, Data, and AI solutions can help accelerate your growth.